[Unite2019] 「禍つヴァールハイト」最大100人同時プレイ!モバイルオンラインゲームの実装テクニック
動画・スライド:https://learning.unity3d.jp/3345/
平井 佑樹 KLab株式会社
稲田 真吾 KLab株式会社
西那 康志 KLab株式会社
学んだ知見
- 100人同時接続を実現するために
- オブジェクトの再利用(newを抑える)
- 同期ずれ
- 重複した通知は最後の値のみ適用
- アセットバンドルロード
- ロードの優先度
- UI > ミッションに関連するもの > カメラに近いプレイヤー
- ロードの優先度
- アセットダウンロード
- 並列化, Rangeリクエスト
- データ量が増えてもがロード長くならない
- 並列化, Rangeリクエスト
講演概要
通信基盤の紹介
RPCクライアント(Remote Procedure Call)
- [クライアント]c# メソッド実行 <-> goの関数実行[サーバ]
受信処理のチューニング
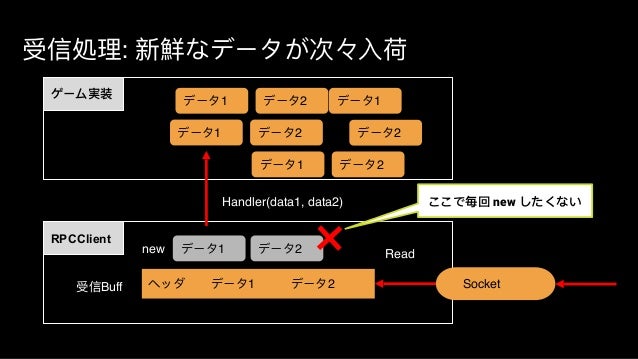
リアルタイムバトル実装
課題
- スペックの差により、サーバから送られてくる通知をさばける量が違う
原因
- 通知処理に1フレーム以上の時間がかかる
- エフェクト周りが重い
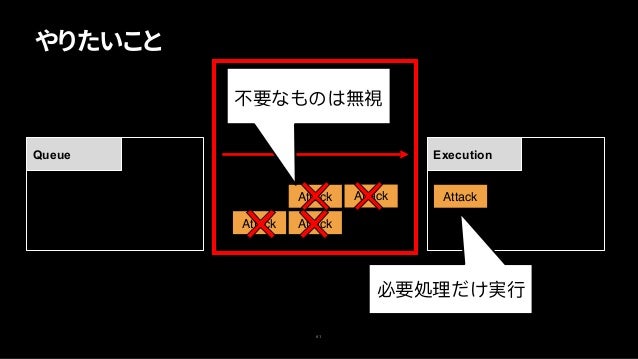
対策
- 不要な通知を無視する
- サーバからの通知は上書き更新
- 実行時刻が過去のものを無視
アセットロードの負荷軽減
課題
- プリロードできない
- 操作中のロード負荷
対策
- priorityによるロード順の制御
- UI、プレイヤー、敵の優先度
- 操作中のロード不可の軽減
- FPSに応じて並列ロード数を動的
- instantiateの高速化
- キャッシュ

アセットダウンロードの高速化
課題1
- 進行に応じで都度DLができない
- プレイヤーが何を装備しているかわからない
対策1
- メインスレッドを使わない(
WWW/UnityWebRequestを使わない) - コネクション数を増やす
課題2
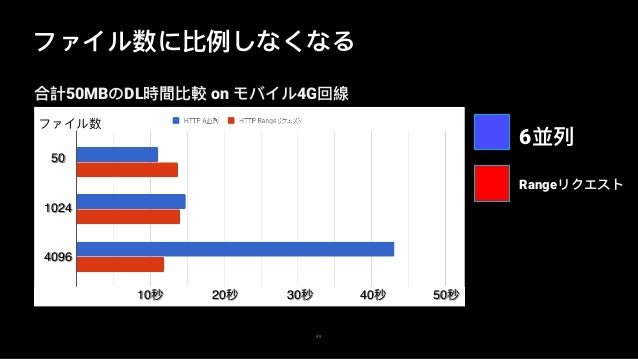
- まだファイル数に依存して時間がかかる
対策2
- まとめてDLして受信後に展開
- Rangeリクエスト
所感
- 随時DLが使えない場合の対策としてとてもよくまとまっている内容だと思った
- SINoALICEとの比較
- HTTP/2を実装できない場合、こちらの対処法を使うことができればある程度緩和できそう
[Unite2019] Unityだったら簡単!マルチプレイ用ゲームサーバ開発 ~実践編~
動画・スライド:https://learning.unity3d.jp/3341/
小端 みより 株式会社ミクシィ
学んだ知見
Unityサーバを利用することで、
クライアントエンジニアでもサーバ構築が可能
- c#で実装できる
- Unity機能が使える(Animation, Physics, AIなど)
- プロファイラが使える!!
- 単一プロジェクトで管理
サーバ処理型で実装できる
- チート耐性が高い
- 通信が安定する
- クライアントの処理負荷を軽減できる
講演概要
Unityサーバを作にあたって
- メリット
- ミドルウェアやサービスが豊富
- 手軽
- デメリット
- チートされやすい
- 通信が不安定になりやすい
- 大規模タイトルに向かない
→ サーバ処理型にすればいいのでは?
Unityサーバとは
- Unityで作る専用サーバ
- c#で実装できる
- Unity機能が使える(Animation, Physics, AIなど)
- クライアント、サーバ両方を単一プロジェクトで管理
作成するゲームの概要
7つの課題と解決法
1. どの通信ライブラリを使えばいい?
- 公式
- Unity Transport Package
- DOTS
- 非公式
- LiteNetLib
ゲーム設計によってどういう実装をすればいいかのフローチャートも参考に
https://blogs.unity3d.com/2019/06/13/navigating-unitys-multiplayer-netcode-transition/
結論:
LiteNetLibを採用
API実装がある程度かたまっている
2. TCPとUDPどっちを使う?
初めて使うならTCP
- ポピュラーで情報が多い
- プロトコルとして信頼性が高い
しかし、リアルタイム性という点においてTCPの再送制御は致命的
結論:UDPを採用
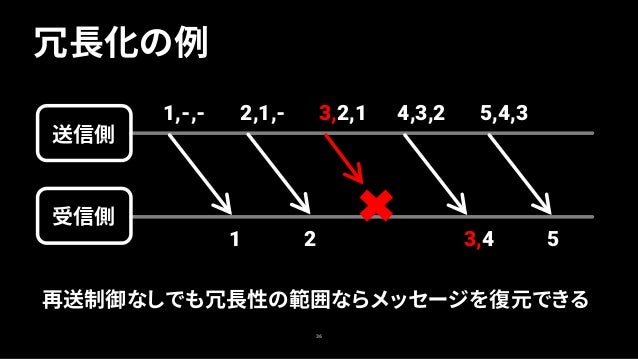
3. 再送制御による遅延を回避するには?
送信メッセージを冗長化
4. MTUって何?
Maximum Transmission Unit
- 1回の通信で転送可能なデータグラムの上限サイズ
- 超過した場合は分割される or そもそも到達しない
対処法
- メッセージサイズを削減する
- プレイヤー視界外のオブジェクトをカリング
- オブジェクトの距離、優先度に応じて通信タイミングを分散させる
- データを圧縮
- デルタ圧縮
- 送信内容をキャッシュする
- 更新されたオブジェクト、プロパティのみを送信
結論:上記のテクニックでメッセージサイズを削減
5. ラグはなくせるのか?
一般的にラグ = 通信遅延と思われているが非常に小さい(1, 2ms)
実際は再送制御の遅延、通信サイクルに起因するもののほうが大きい
入力のアップデートのタイミングが悪いと必ず起こる宿命
→ 体感上のラグを打ち消す
例)

結論:
オンラインゲームにおいてラグは宿命
体感上のラグを減らす工夫をする
6. サーバとクライアントで同一プロジェクト管理できる?
ビルド設定で使用するアセットを切り替えればよい
クライアント・サーバのどちらで必要なアセットかを区別する

結論:
シーン/アセットをどちらで使うかビルド時に判別・切り替え
→ AssemblyDefinitionを利用
7. 専用サーバをどうやって運用したらいい?
ホスティングサービスの利用
結論:GameLiftを採用
所感
- Unityでサーバ構築をできることを知らなかったのでとても参考になった
- 結局サーバ構成を考える部分が生じるのでサーバエンジニアは必要そう
- 1日目の講演であったGame Server Services(GS2)と両立できるのかが気になった
[Unite2019] 大量のアセットも怖くない!~HTTP/2による高速な通信の実装例~
動画・スライド:https://learning.unity3d.jp/3330/
竹原 涼 株式会社セガゲームス
山田 英伸 株式会社セガゲームス
学んだ知見
結論:HTTP/2でのダウンロードがおすすめ

講演概要
HTTP/2特徴
- stream多重化(TCP)
- HTTP/1.1は6コネクションくらい
- HTTP/2は100以上が推奨
- レスポンスを待たずに通信が可能
- ウィンドウサイズ制御(TCPのウィンドウサイズではない)
- 受信バッファあふれを防ぐ
- ヘッダ圧縮
- HPACKフォーマット(ヘッダサイズが減る)
- バイナリフレーム
- 通信データがテキストデータからバイナリに
ダウンロード特性の解説
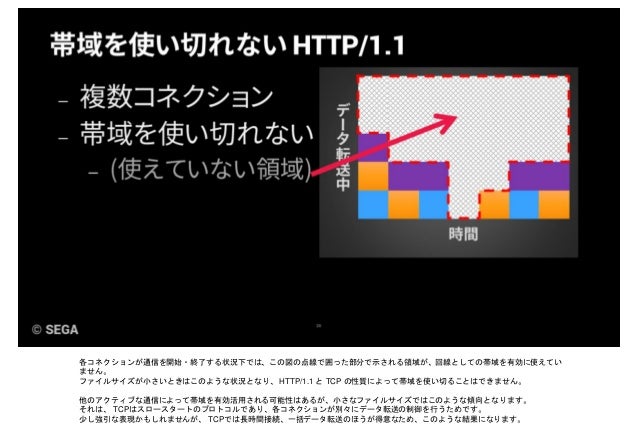
HTTP/1.1では帯域を使い切れない
- 小さいファイルの転送では帯域が余る
- HoLBの仕様
帯域を無駄にしないHTTP/2
- 転送が終了したらすぐ別のストリームが開始される
- ストリームが複数動いたら帯域を分配する
- HoLB解消
- リクエストを送りながらレスポンスを受け取れる

HTTP/2の弱点
- 下層がTCPのためパケット欠損でHoLBが発生しうる
HoLBはHTTP/3で解決?
まだドラフトの状態
HTTP/2通信の実装の注意点
そのため登壇者はc/c++で実装した
2019/8現在もc#で利用できるモジュールは存在してない
所感
- アセットバンドルのDLを高速化したい場合はこの方法が良いとおもいました
- ただし開発工数がそれなりに掛かりそうなので要注意
- 今後HTTP/2対応が進んだ場合は優先的に対応を進める価値はありそう